
AntConc, logiciel d'analyse textuelle
Frédéric Weiss (CID, ENS de Lyon)
AntConc est un logiciel d'analyse textuelle développé par M. Laurence Anthony, professeur à l'université de Waseda au Japon. Il est gratuit et téléchargeable pour les systèmes Windows, Mac et Linux, à l'adresse suivante <http://www.laurenceanthony.net/software/antconc/>
On présente ici la version 3.3.5 pour Windows [1]. Le fichier téléchargé est un fichier exécutable nommé AntConc.exe. Il suffit de double-cliquer dessus pour lancer l'application. Il n'y a pas d'installation préliminaire.
3. Outil "Word List" (index lexical)
4. Outil "Concordance" (concordance)
5. Outil "Concordance Plot" (distribution)
6. Outil "File View" (contexte élargi)
7. Outil "Clusters/N-Grams" (agrégats)
8. Outil "Collocates" (cooccurrences)
10. Utilisation d'expressions régulières
1. Textes au format brut
À titre d'exemple, on veut analyser les deux premiers livres des Fables de La Fontaine. Pour cela, le texte doit être disponible au format brut sous forme de fichiers TXT – c'est le type de fichier associé par défaut au bloc-notes de Windows. On a donc préparé deux fichiers nommés « fables_livre1.txt » et « fables_livre2.txt ».
1.1. Encodage des caractères
Le bloc-notes permet d'enregistrer un texte brut dans les encodages ANSI ou Unicode. Le logiciel AntConc accepte les deux.
L'encodage ANSI (American National Standards Institute) est une survivance des anciennes versions de Windows. Il s'agit en fait du standard Windows 1252. C'est un jeu de 256 caractères visible sur le site Microsoft Developer Network à l'adresse suivante <https://msdn.microsoft.com/fr-fr/goglobal/cc305145.aspx>. Chaque caractère est représenté par un octet dans le fichier texte. Historiquement, ce standard est une extension de la norme ISO 8859-1, plus connue sous le nom d'ISO Latin-1. Celle-ci n'avait pas utilisé les codes 128 à 159 (80 à 9F en hexadécimal), Microsoft a exploité cette « lacune » pour ajouter ses propres caractères.
L'encodage Unicode est le standard actuel de la bureautique et d'Internet. Le site de référence est celui du consortium Unicode <http://www.unicode.org/>. Plus de 100 000 caractères sont définis à ce jour. Il faut donc plusieurs octets pour représenter les caractères Unicode. Pour cela, il existe différentes solutions techniques, ce qui explique les variantes Unicode, Unicode big endian et UTF-8 disponibles dans le bloc-notes – se référer à la rubrique Encodage de la boîte Enregistrer sous (version Windows 7).
Le développement d'Internet a consacré l'encodage UTF-8. La plupart des bases textuelles en ligne proposent cet encodage par défaut. On a donc tout intérêt à travailler avec des textes bruts encodés en UTF-8.
1.2. Préparation minimale
Le découpage automatique d'un texte en mots s'appuie sur la distinction entre deux classes de caractères : les séparateurs tels que l'espace et les signes de ponctuation, et les non séparateurs tels que les lettres. Mais en français, il faut tenir compte du statut particulier de l'apostrophe qui sépare, tout en faisant partie des mots élidés. Ainsi, le découpage d'un contexte comme « j'en suis fort aise » doit produire « j' », « en », « suis », « fort » et « aise ».
Une solution simple consiste à considérer l'apostrophe comme un caractère non séparateur et à la remplacer par la séquence apostrophe-espace dans le texte-même (cf. figure 1). Ce faisant, on maltraite le mot « aujourd' hui » qu'il faut rétablir en « aujourd'hui » (1 occurrence dans le texte) [2].
Figure 1. Texte brut préparé
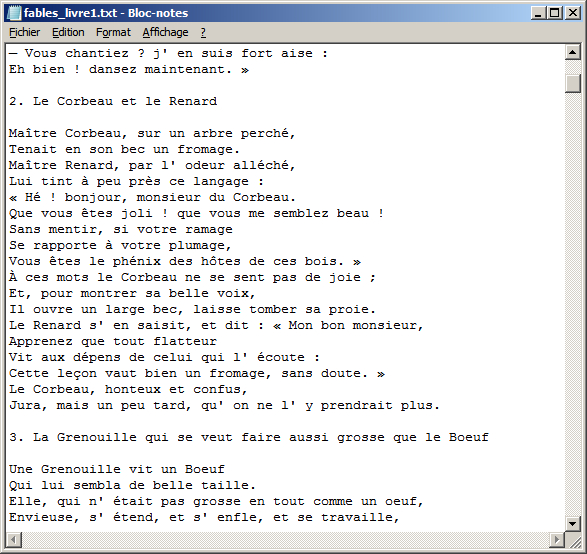
Il est possible que, dans un texte, l'apostrophe (code = 39) soit remplacée par le guillemet simple fermant « ’ » (code = 8217). Ceci provient généralement des logiciels de traitement de texte qui effectuent cette substitution de manière automatique au cours de la frappe. Dans ce cas, on remplacera le guillemet simple fermant par l'apostrophe avant d'effectuer le traitement précédent.
Pour simplifier les recherches ultérieures, on peut aussi remplacer les ligatures éventuelles « œ » (« Œ », « æ », « Æ ») par des séquences « oe » (« OE », « æ », « AE »).
1.3. Et les textes balisés ?
AntConc accepte les textes balisés aux formats HTML ou XML. L'intérêt est cependant limité compte tenu du fait que le balisage n'est pas exploitable. Par exemple, dans un texte HTML, on ne peut pas demander au logiciel de rechercher un mot dans les titres uniquement, c'est-à-dire dans des paragraphes marqués par les balises <H1> à <H6>. D'autres part, les entités de caractères ne sont pas reconnues. Ainsi, dans l'expression « Maître Corbeau », l'entité « î » n'est pas traitée comme un « î ». Il faut donc préalablement remplacer toute entité par le caractère qu'elle représente.
2. Lancement d'AntConc
2.1. Fenêtre principale
Dans AntConc, on sélectionne un ou plusieurs fichiers avec la commande File/Open File(s).
Figure 2. Fenêtre principale d'AntConc
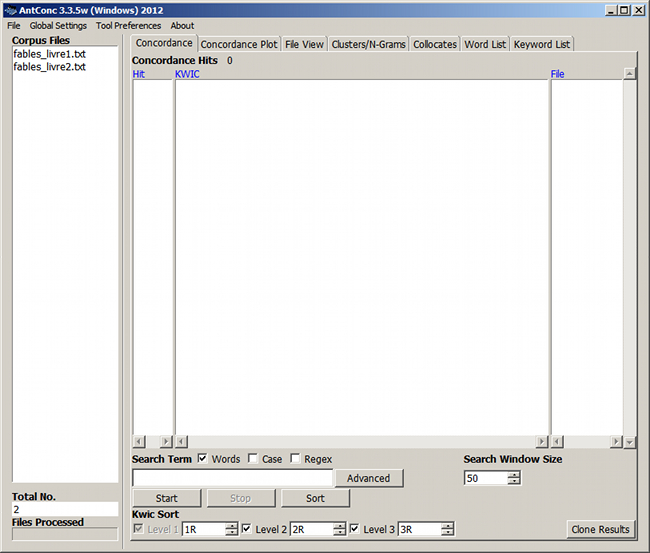
Le volet de gauche Corpus Files affiche les fichiers sélectionnés.
Le volet central contient sept onglets correspondant aux différents outils proposés par AntConc : Concordance, Concordance Plot, File View, Clusters/N-Grams, Collocates, Word List, Keyword List. Ils sont directement activables à l'aide des raccourcis F1 à F7. L'outil Keyword List n'est pas abordé dans ce document.
2.2. Paramètres généraux
Avant de traiter un texte, il est impératif de paramétrer correctement la session de travail. La commande Global Settings permet d'accéder aux paramètres généraux. On peut sauvegarder le paramétrage dans un fichier externe comme expliqué ci-après.
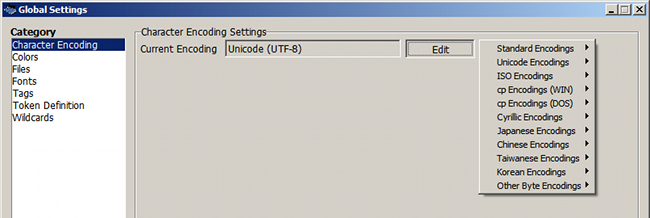
Rubrique "Character Encoding"
Cette rubrique est primordiale car elle permet de spécifier l'encodage du texte à étudier. La valeur par défaut est UTF-8. On la conserve.
Pour sélectionner un autre encodage, cliquer sur le bouton Edit . Un menu contextuel s'affiche. On trouve notamment les encodages Unicode (Unicode Encodings), ISO (ISO Encodings) et Windows (cp Encodings (WIN)).
Figure 3. Encodage des textes
Rubrique "Token Definition"
Cette rubrique est primordiale car elle permet de spécifier les caractères NON SÉPARATEURS – on ne peut pas spécifier directement la liste des séparateurs, ce qui serait plus simple.
Figure 4. Caractères non séparateurs
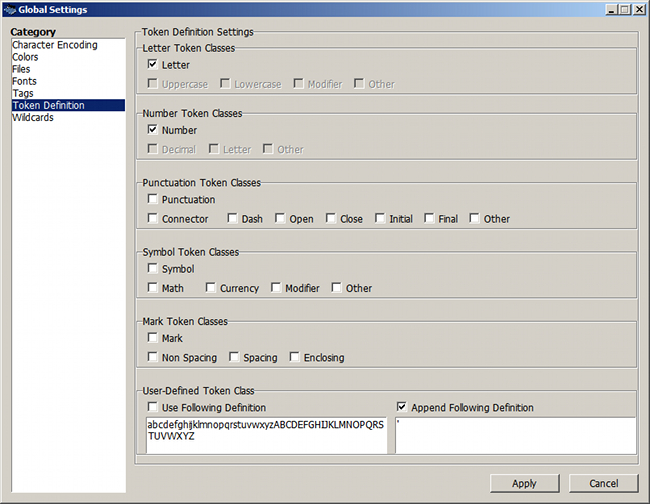
La méthode la plus directe consiste à cocher des catégories de caractères – rubriques Letter Token Classes à Mark Token Classes. Le logiciel se réfère aux catégories officielles d'Unicode, chaque caractère étant rangé dans une catégorie et une seule [3].
On choisit donc les lettres (Letter) et les chiffres (Number). Quant à l'apostrophe, elle est classée dans la catégorie Punctuation, Other. Pour la déclarer non séparateur, il faut activer la zone Append Following Definition et la taper dedans (voir figure 4). Selon le texte à étudier, il peut être utile d'ajouter d'autres caractères non séparateurs dans cette zone, notamment des symboles tels que « % » ou « & ».
Une autre méthode pour déclarer les caractères non séparateurs consiste à activer la zone Use Following Definition et à les taper dedans in extenso.
Autres rubriques
La rubrique Tags permet de gérer l'affichage des balises quand on traite des textes au format HTML ou XML. La rubrique Wildcards permet de redéfinir, le cas échéant, les jokers utilisables dans les formules de recherche. Les rubriques Colors, Files, Fonts sont secondaires.
2.3. Paramètres spécifiques
La commande Tool Preferences regroupe les paramètres des outils Concordance, Clusters/N-Grams, Collocates, Word List, Keyword List (se reporter aux sections correspondantes ci-dessous).
2.4. Sauvegarde du paramétrage
Quand on quitte AntConc, le paramétrage est perdu à moins de le sauvegarder dans un fichier externe. Pour cela, lancer la commande File/Export Settings to File. Les paramètres généraux et spécifiques sont sauvegardés, ainsi que la liste des textes chargés. Par défaut, le fichier généré est nommé « antconc_settings_330.ant ».
Par la suite, si on a conservé le nom par défaut, le fichier est automatiquement chargé au démarrage d'AntConc, sinon il faut lancer la commande File/Import Settings from File.
3. Outil "Word List" (index lexical)
3.1. Principe
Cet outil produit l'index lexical des textes sélectionnés :
- Cliquer sur le bouton Start.
Au-dessus de l'index sont indiqués le nombre de formes (Word Types) et le nombre d'occurrences (Word Tokens) trouvées.
En cliquant sur un mot de la liste, on affiche sa concordance – l'onglet Concordance est activé.
Figure 5. Index lexical
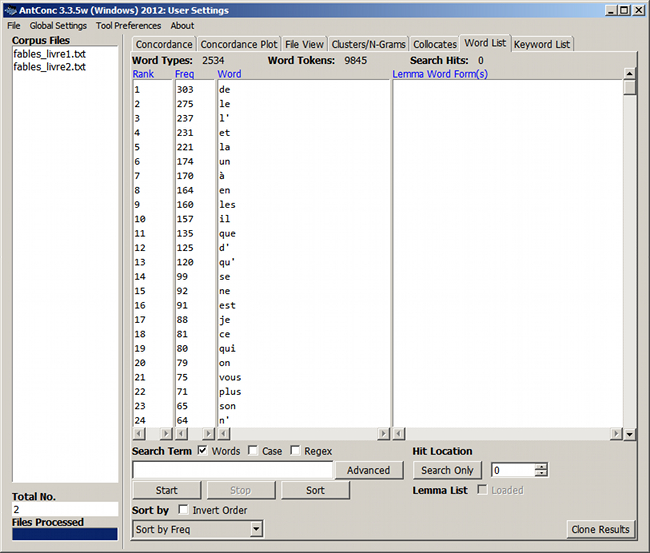
N.B. On peut faire défiler l'index avec les touches de défilement vertical après avoir cliqué dans une colonne.
3.2. Tri de l'index
Pour trier l'index courant :
- Choisir un type de tri (rubrique Sort by) : Sort by Freq (tri hiérarchique), Sort by Word (tri pseudo-alphabétique), Sort by Word End (idem en parcourant les mots de droite à gauche).
- Cocher l'option Invert Order pour inverser le sens du tri, si nécessaire.
- Cliquer sur le bouton Sort.
Dans l'ordre pseudo-alphabétique (terme non officiel), les caractères sont classés selon leur code informatique. Les formes commençant par une lettre accentuée sont donc reléguées en fin de liste. Il n'est pas possible de trier dans l'ordre alphabétique usuel.
3.3. Recherche dans l'index
Cette fonction de recherche se retrouve dans tous les onglets. Ici, la recherche s'effectue dans l'index-même :
- Taper un mot dans la ligne de saisie.
- Cliquer sur le bouton Search Only (ou touche Entrée).
L'index est calé sur l'entrée correspondante si elle existe. Celle-ci est surlignée en noir.
La rubrique Search Term définit deux modes de recherche :
Mode normal (= option Regex désactivée).
L'expression tapée est recherchée en tant que mot entier si l'option Words est activée, en tant que sous-chaîne sinon. L'option Case permet de tenir compte de la casse des caractères. On peut utiliser les jokers définis dans la rubrique Wildcards de la boîte Global Settings.
Mode Regex (= option Regex activée).
L'expression tapée est interprétée en tant qu'expression régulière – Regex signifie regular expression. Cf. § Utilisation d'expressions régulières.
Le bouton Advanced est détaillé ci-après.
3.4. Sauvegarde des résultats
La commande File/Save Output to Text File sauvegarde l'index complet au format texte tabulé (fichier TXT).
3.5. Paramètres spécifiques
La rubrique Tool Preferences/Word List regroupe les paramètres de l'outil Word List. Elle sert essentiellement à l'utilisation de listes dites pick list, stop list et lemma list (cf. § Utilisation de listes). On conserve l'option Treat all data as lowercase (pas de distinction entre majuscules et minuscules), sinon les mots en début de phrase (ou de vers) créent des distinctions abusives telles que « Le » et « le », « Un » et « un », etc.
4. Outil "Concordance" (concordance)
4.1. Principe
Cet outil produit la concordance d'un ou plusieurs mots au format KWIC (KeyWord In Context) :
- Taper un mot dans la ligne de saisie.
- Régler la longueur des contextes dans la rubrique Search Window Size (valeur N variant de 0 à 1000 par pas de 5, pour un contexte de longueur total 2 × N).
- Cliquer sur le bouton Start.
La rubrique Concordance Hits donne le nombre de contextes trouvés.
En cliquant sur une occurrence du mot pivot, on affiche son contexte élargi – l'onglet File View est activé.
Figure 6. Concordance du mot « renard »
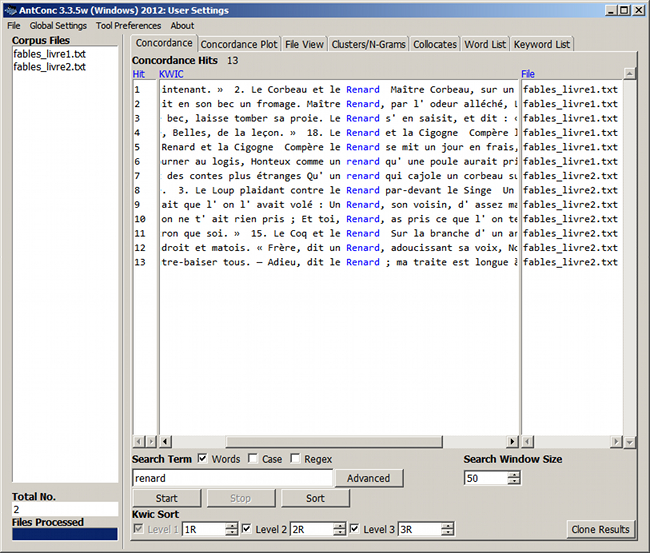
4.2. Tri des contextes
Par défaut, les contextes sont triés dans l'ordre chronologique. La rubrique Kwic Sort permet de trier les contextes en fonction des mots placés à gauche et à droite du mot pivot :
- Activer 1, 2 ou 3 niveaux de tri (Level 1, Level 2, Level 3).
- Choisir, pour chaque niveau, la position du mot qui régit le tri. Le mot pivot est représenté par « 0 », le premier mot à gauche par « 1L », le premier à droite par « 1R », le deuxième à gauche par « 2L », le deuxième à droite par « 2R », etc.
- Cliquer sur le bouton Sort.
Le tri par niveau suit l'ordre pseudo-alphabétique vu précédemment.
Pour revenir au tri par ordre chronologique, cliquer sur le bouton Start.
4.3. Recherche de contextes
La recherche s'effectue dans le texte-même. On peut travailler en mode normal ou en mode Regex (cf. § Recherche dans l'index).
Le bouton Advanced donne accès à la recherche avancée qui permet d'utiliser des listes de mots :
- Cocher l'option Use search term(s) from list below.
- Taper les mots (un par ligne) ou charger une liste au format TXT dans le même encodage que les textes (bouton Load File).
- Cliquer sur le bouton Apply pour valider la liste.
Figure 7. Recherche d'une liste de mots
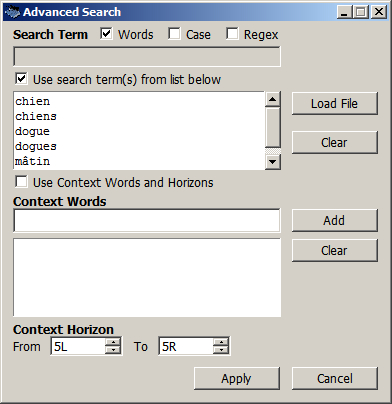
Les éléments de la liste sont interprétés selon le mode de recherche choisi dans la rubrique Search Term (mots entiers, sous-chaînes, expressions régulières).
Comme l'outil opère plein texte, il peut rechercher des mots composés, des locutions et toute expression contenant des séparateurs. Par exemple, « cul-de-jatte », « à jeun », « c' est-à-dire » (noter la séquence apostrophe-espace eu égard au traitement préliminaire du texte).
4.4. Sauvegarde des résultats
La commande File/Save Output to Text File sauvegarde les contextes trouvés au format texte tabulé (fichier TXT).
4.5. Paramètres spécifiques
La rubrique Tool Preferences/Concordance regroupe les paramètres de l'outil Concordance. Elle contient essentiellement des options réglant l'affichage des résultats.
L'option Put delimiter around hits in KWIC display permet de séparer le mot pivot de ses contextes gauches et droits par des tabulations, par exemple. La sauvegarde des résultats produit un fichier TXT utilisable dans un tableur, les contextes étant automatiquement découpés en trois colonnes : la colonne des contextes gauches, celle du mot pivot et celle des contextes droits.
5. Outil "Concordance Plot" (distribution)
5.1. Principe
Cet outil affiche la distribution des occurrences d'un ou plusieurs mots :
- Taper un mot dans la ligne de saisie.
- Cliquer sur le bouton Start.
La rubrique Concordance Hits donne le nombre d'occurrences trouvées. Un texte est représenté par un bandeau (plot), une occurrence par une barre verticale noire.
En cliquant sur une barre verticale, on affiche le contexte élargi – l'onglet File View est activé. La rubrique Plot Zoom permet de grossir l'affichage pour mieux discerner les barres.
Figure 8. Distribution du mot « maître »
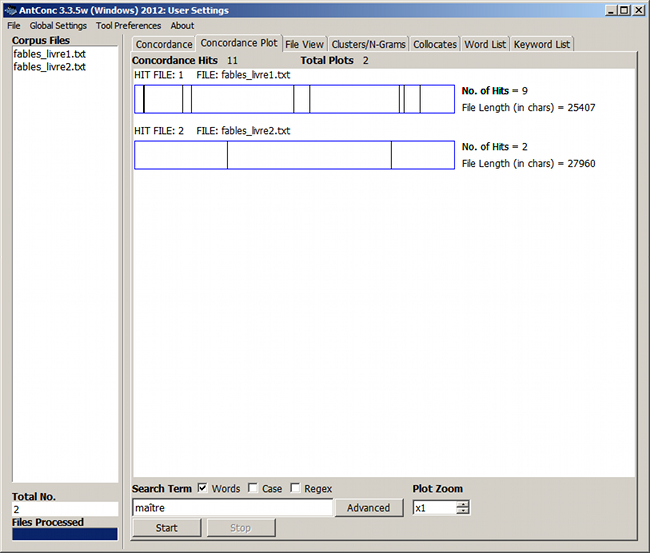
5.2. Recherche de distributions
Même fonctionnement que pour l'outil Concordance.
5.3. Sauvegarde des résultats
Pas de sauvegarde pour l'outil Concordance Plot.
5.4. Paramètres spécifiques
Pas de paramétrage spécifique pour l'outil Concordance Plot.
6. Outil "File View" (contexte élargi)
6.1. Principe
Cet outil est similaire à la fonction de recherche d'un éditeur de texte (recherche dit plein texte) :
- Taper un mot dans la ligne de saisie.
- Cliquer sur le bouton Start.
Si la recherche fournit plusieurs résultats, leur nombre est indiqué au-dessus du texte (File View Hits), on les parcourt à l'aide du compteur Hit Location.
En cliquant sur une occurrence, on affiche sa concordance – l'onglet Concordance est activé.
Figure 9. Occurrence du mot « maître » dans le texte
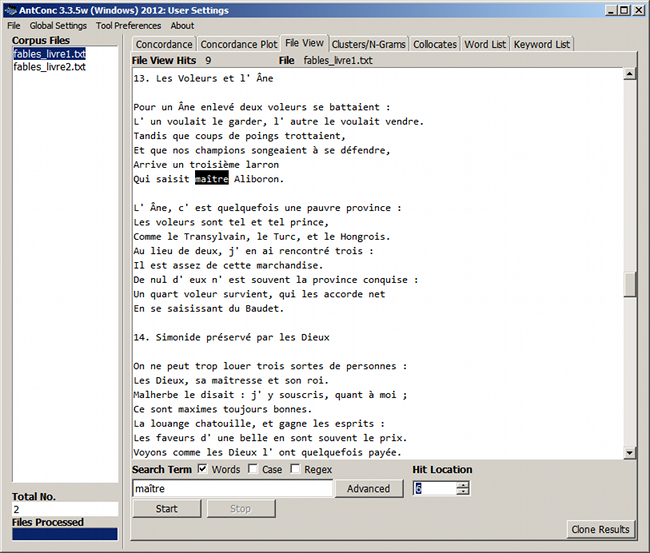
6.2. Recherche de mots
Même fonctionnement que pour l'outil Concordance.
6.3. Sauvegarde des résultats
La commande File/Save Output to Text File sauvegarde le texte entier ce qui ne présente aucun intérêt.
7. Outil "Clusters/N-Grams" (agrégats)
7.1. Principe
Cet outil produit une liste d'agrégats (groupes de mots contigus) contenant un mot pivot :
- Taper un mot dans la ligne de saisie.
- Régler les longueurs minimale (Min.) et maximale (Max.) des agrégats dans la rubrique Cluster Size (en nombre de mots, de 1 à 100, mot pivot inclus).
- Tous les agrégats sont recherchés, le mot pivot pouvant apparaître dans n'importe quelle position sauf si on coche l'option On Left (ou On Right) pour ne conserver que les agrégats commençant (ou se terminant) par le mot pivot.
- Cliquer sur le bouton Start.
Noter qu'un agrégat peut contenir des caractères séparateurs, mais il ne peut pas excéder un paragraphe.
Au-dessus des résultats, on trouve le nombre total d'agrégats (Cluster Tokens) et le nombre d'agrégats différents (Cluster Types). La colonne Range indique le nombre de fichiers dans lequel l'agrégat apparaît.
En cliquant sur un agrégat de la liste, on affiche sa concordance – l'onglet Concordance est activé.
Figure 10. Agrégats de longueur 2 à 3 commençant par le mot « tout »
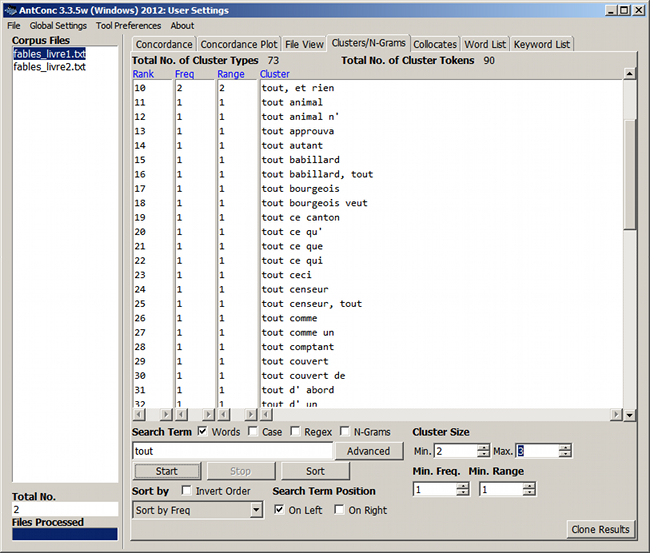
L'outil Clusters est particulièrement utile pour détecter des formules répétitives dans un texte – en analyse textuelle, on parle de segments répétés. Dans cette optique, il faut fixer une fréquence minimale supérieure à 1 :
- Incrémenter le compteur Min. Freq. jusqu'à la fréquence souhaitée.
- Cliquer sur le bouton Start.
Par défaut, les majuscules et les minuscules sont indifférenciées dans les agrégats, ce qui maximise les regroupements possibles. On peut modifier ce paramètre comme expliqué ci-dessous.
7.2. N-Grams
Quand on active l'option N-Grams dans la rubrique Search Term, l'outil produit tous les agrégats ayant les longueurs minimale et maximale spécifiées dans la rubrique N-Gram Size – on ne tape donc pas de mot pivot particulier.
7.3. Tri des agrégats
Similaire à l'outil Word List.
7.4. Recherche d'agrégats
Même fonctionnement que pour l'outil Concordance.
7.5. Sauvegarde des résultats
La commande File/Save Output to Text File sauvegarde la liste des agrégats trouvés au format texte tabulé (fichier TXT).
7.6. Paramètres spécifiques
La rubrique Tool Preferences/Clusters/N-Grams regroupe les paramètres de l'outil Clusters/N-Grams. Elle contient essentiellement des options réglant l'affichage des résultats.
L'option Treat all data as lowercase est importante car elle permet de ne pas différencier les majuscules des minuscules dans les agrégats, ce qui favorise les regroupements possibles.
8. Outil "Collocates" (cooccurrences)
8.1. Principe
Cet outil produit les cooccurrences (ou collocations) d'un mot pivot :
- Taper un mot dans la ligne de saisie.
- Régler, dans la rubrique Window Span, la distance de recherche à gauche et à droite du mot pivot à l'aide des valeurs « 0 », « 1L », « 1R », « 2L », « 2R »… (notation déjà évoquée). Par exemple, avec la distance « From 2L To 3R », tout mot rencontré à partir du 2e mot à gauche du mot pivot jusqu'au 3e mot à droite est considéré comme cooccurrent.
- Cliquer sur le bouton Start.
Noter que la recherche de cooccurrences ne tient pas compte des limites de paragraphe (seule la distance de recherche compte).
Au-dessus des résultats, on trouve le nombre total de cooccurrences (Collocate Tokens) et le nombre de cooccurrences différentes (Collocate Types).
Les mots cooccurrents apparaissent dans la colonne Collocate. Leur fréquence est affichée (colonne Freq) et décomposée en fréquences à gauche (Freq(L)) et à droite (Freq(R)) du mot pivot. La colonne Stat est mystérieuse.
En cliquant sur un mot cooccurrent, on affiche sa concordance complète et non pas, hélas, les seuls contextes où il apparaît avec le mot pivot.
Figure 11. Cooccurrences du mot « loup »

L'outil Collocates est particulièrement utile pour détecter les associations plus ou moins directes de mots dans un texte. Pour mieux repérer les cooccurrences répétitives, on peut fixer une fréquence minimale supérieure à 1 :
- Incrémenter le compteur Min. Collocate Frequency jusqu'à la fréquence souhaitée.
- Cliquer sur le bouton Start.
Par défaut, les majuscules et les minuscules sont indifférenciées dans les cooccurrences, ce qui maximise les regroupements possibles. On peut modifier ce paramètre comme expliqué ci-dessous.
8.2. Tri des cooccurrences
Similaire à l'outil Word List. S'ajoute la possibilité de trier par fréquence à gauche ou fréquence à droite.
8.3. Recherche de cooccurrences
Même fonctionnement que pour l'outil Concordance.
8.4. Sauvegarde des résultats
La commande File/Save Output to Text File sauvegarde la liste des cooccurrences trouvées au format texte tabulé (fichier TXT).
8.5. Paramètres spécifiques
La rubrique Tool Preferences/Collocates regroupe les paramètres de l'outil Collocates. Elle contient essentiellement des options réglant l'affichage des résultats.
L'option Treat all data as lowercase est importante car elle permet de ne pas différencier les majuscules des minuscules dans les cooccurrences, ce qui favorise les regroupements possibles.
L'option Collocation measure est à désactiver si l'on souhaite se débarrasser de la colonne Stat.
9. Utilisation de listes
9.1. Recherche d'une liste de mots
Dans chacun des onglets précédents, on a vu que la recherche avancée (bouton Advanced) permet de rechercher une liste de mots ou expressions (cf. § Recherche de contextes).
9.2. Index partiel (pick list)
Le principe consiste à produire un index à partir d'une liste de mots, dite pick list.
- Lancer la commande Tool Preferences, rubrique Word List.
- Dans la sous-rubrique Word List Range, cocher l'option Use specific words below.
Figure 12. Mise en œuvre d'une « pick list »
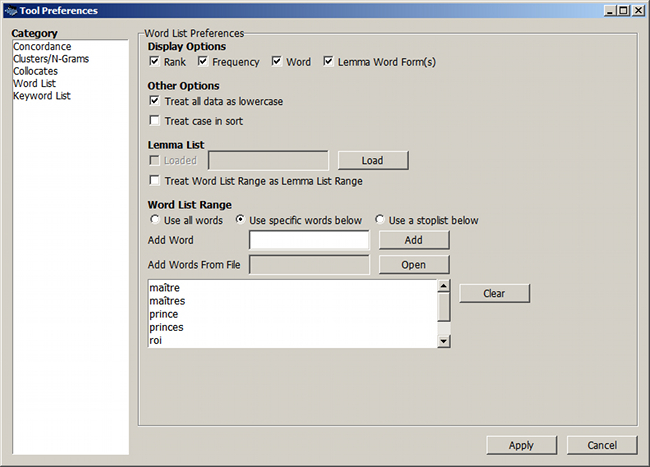
- Taper les mots un par un (zone Add Word, puis bouton Add) ou charger une liste au format TXT dans l'encodage courant (bouton Open) – dans le bloc-notes de Windows, il suffit de taper une expression par ligne.
- Valider avec le bouton Apply.
- Produire l'index avec l'outil Word List.
On ne peut pas utiliser d'expression régulière, ni de séparateur dans une pick list. Par exemple, « chien* » ou « à jeun » ne produisent pas le résultat escompté. Il faut donc taper toutes les formes recherchées.
9.3. Index filtré (stop list)
Le principe consiste à produire un index complet, puis à évacuer automatiquement une liste de mots, dite stop list.
- Lancer la commande Tool Preferences, rubrique Word List.
- Dans la sous-rubrique Word List Range, cocher l'option Use a stoplist below.
- La suite est similaire au cas précédent.
Une stop list est généralement utilisée pour évacuer les mots outils (articles, prépositions, etc.).
9.4. Index lemmatisé (lemma list)
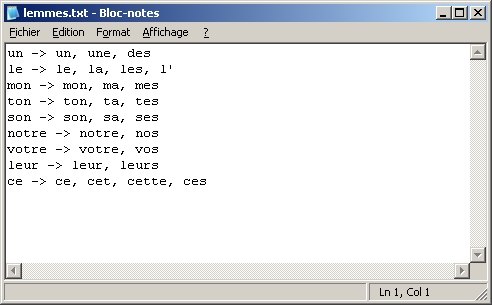
Il faut d'abord fabriquer une liste de lemmes, dit lemma list, directement dans le bloc-notes de Windows :
- Taper une ligne de la forme suivante pour chaque lemme :
lemme -> form1, form2, … (mettre un séparateur entre chaque forme).
- Enregistrer la liste.
Figure 13. Liste de lemmes
Dans AntConc :
- Lancer la commande Tool Preferences, rubrique Word List.
- Dans la sous-rubrique Lemma List, charger la liste précédente en cliquant sur le bouton Load – une fenêtre secondaire montrant la lemma list s'affiche.
Figure 14. Liste analysée par AntConc
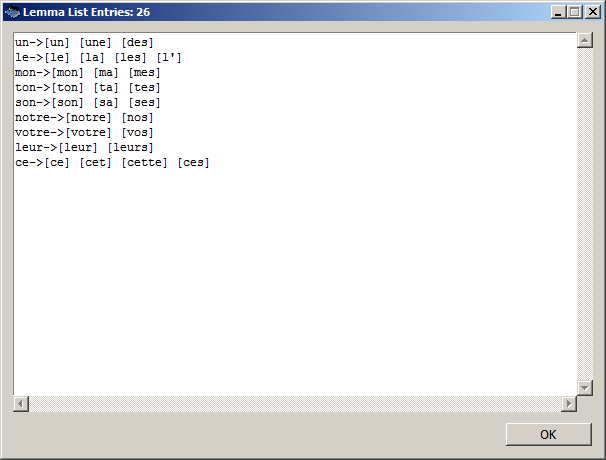
- Valider avec le bouton Apply.
- Produire l'index avec l'outil Word List.
Les formes ayant une correspondance dans la liste de lemmes sont regroupées sous leur forme canonique (colonne Lemma). La colonne Lemma Word Form(s) montre alors les flexions trouvées avec leur fréquence, la colonne Freq contient la somme de ces fréquences.
Pour les autres formes, sans correspondance, il ne se produit rien de plus que pour une indexation ordinaire.
Figure 15. Index (partiellement) lemmatisé
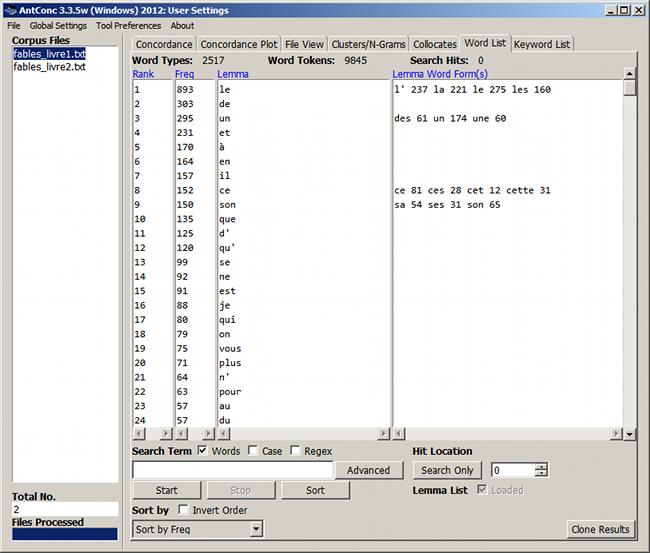
Un clic sur une forme canonique (colonne Lemma) ne montre que la concordance de celle-ci et non pas du lemme tout entier – et on ne peut pas cliquer sur les flexions. Dommage…
10. Utilisation d'expressions régulières
Les outils d'AntConc permettent d'effectuer des recherches à base d'expressions régulières. Il faut pour cela cocher l'option Regex dans la rubrique Search Term. La syntaxe adoptée est celle du langage de programmation Perl.
Ci-après, quelques exemples illustrant les éléments syntaxiques fondamentaux [4] :
bille
Trouve « bille » en tant que sous-chaîne dans les mots « bille », « billevesée », « escarbilles », par exemple.
Bille
Trouve « Bille » en tant que sous-chaîne, mais pas « bille ». La casse des caractères compte.
b.lle
Cherche « balle », « belle », « bille », etc. Le point signifie « n'importe quel caractère ».
b\.lle
Cherche « b.lle ». L'anti-slash neutralise l'interprétation des caractères réservés. Les caractères réservés sont : $ ( ) * + - . ? [ \ ] ^ { | }
\bcale
Trouve « cale » en début de mot, par exemple dans « calepin ». L'expression « \b » indique une limite de mot, un « mot » étant ici un assemblage constitué de lettres, de chiffres arabes et du caractère de soulignement (underscore).
cale\b
Trouve « cale » en fin de mot, par exemple dans « bancale ».
\bcale\b
Trouve « cale » en tant que mot (à comparer avec le 1e exemple ci-dessus où il est question de sous-chaîne).
b[aeu]lle
Cherche « balle », « belle », « bulle ». L'expression [ ] délimite une liste de caractères à chercher.
b[^aeu]lle
Ne trouve pas « balle », « belle », « bulle ». L'expression [^ ] délimite une liste de caractères à éviter.
b[a-e]lle
Ne trouve pas « bille », « bulle ». L'expression [ - ] délimite une plage de caractères à chercher.
ba*
Cherche « b », « ba », « baa », « baaa », etc. L'opérateur * signifie « zéro, une ou plusieurs fois ».
ba+
Cherche « ba », « baa », « baaa », etc. L'opérateur + signifie « une ou plusieurs fois ».
ba?
Cherche « b » ou « ba ». L'opérateur ? signifie « zéro ou une fois ».
ba{2,4}
Cherche « baa », « baaa », « baaaa ». L'opérateur {n,p} signifie « au moins n fois, au plus p fois » (n < p).
ba{2}
Cherche « baa ». L'opérateur {n} signifie « exactement n fois ».
ba{2,}
Cherche « baa », « baaa », etc. L'opérateur {n,} signifie « au moins n fois ».
(ba){2,4}
Cherche « baba », « bababa », « babababa ». Les parenthèses modifient la portée d'un opérateur.
balle|ballon|boule
Cherche « balle », « ballon », « boule ». L'opérateur | signifie « ou bien » (l'ordre des termes compte).
[1] Les versions ultérieures (3.4) présentent des défaillances dans le traitement des expressions régulières.
[2] Il existe d'autres exceptions dont on pourrait établir une liste (prud'homme, presqu'île…), mais il y aura toujours des cas imprévisibles tels que « v'là » (voilà) ou « p'tit » (petit) à traiter a posteriori.
[3] Sur le site du consortium Unicode, un document intitulé <Unicode Standard Annex #44: Unicode Character Database> présente les catégories de caractères à la section 5.7. La liste des caractères Unicode et de leurs propriétés, intitulée <Unicode Character Database>, est consultable au format brut. Par exemple, à la ligne correspondant au caractère pour cent, on trouve le code hexadécimal 25, le nom officiel PERCENT SIGN, la catégorie Po et d'autres propriétés, vides pour la plupart, séparées par un point-virgule. Ce caractère fait donc partie des ponctuations et non pas des symboles.
[4] Pour une étude approfondie, on pourra se reporter au site web Regular-Expressions.info <http://www.regular-expressions.info/>.
Contact
Centre d'ingénierie documentaire
École normale supérieure de Lyon
15 parvis René-Descartes
BP 7000
69342 Lyon Cedex 07
Tél. (+33) 4 37 37 60 00
Nous contacter par courriel : formations-cid